Big-O 复杂度评估
大O符号用来衡量一个算法,对于能直接影响执行次数的输入值n进行评估并忽略所有常数项,用来评估程序运行的时间和占用内存的效率。
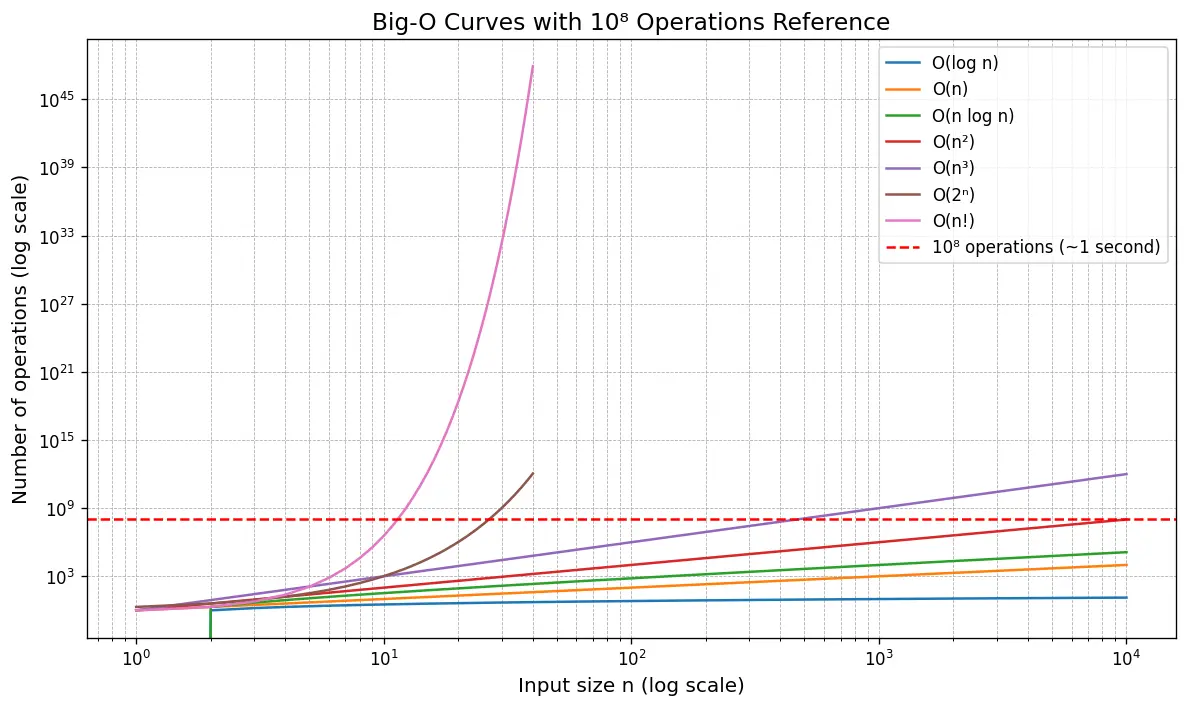 常见的复杂度有上图这些,解题的时间要求标准是1秒,大约在10的8次方
常见的复杂度有上图这些,解题的时间要求标准是1秒,大约在10的8次方
比如输入值n的上限是10^8的话通常会有O(n)或更优的解,使用O(n²)的话会超时
在实际应用中,通过理解代码逻辑就能大致判断其时间复杂度等级,特定的算法在网络上可查询,本篇不做数学式的说明。
常数时间,输入内容不影响程序执行次数
O(log n)
Section titled “O(log n)”log在这里一般默认以2为底,常见的二分查找就是O(log n)
针对已排序的数据,每次通过查找中间点的方式来寻找目标内容
说明:
例如从 1~100 中查找一个数字:
- 第一次查找 50
- 如果目标 > 50 → 在 51~100 之间查找 75
- 如果目标 > 75 → 在 76~100 之间查找 87
- 重复以上过程直到找到目标
示例:
在一个已排序的数组 arr 中判断是否存在元素 item
#include <iostream>#include <algorithm>#include <vector>using namespace std;
// 手写版 - 可自行练习bool BinarySearch(const vector<int>& arr, int item) { int left = 0; int right = arr.size() - 1;
while (left <= right) { int mid = left + (right - left) / 2; if (arr[mid] == item) { return true; } else if (arr[mid] < item) { left = mid + 1; } else { right = mid - 1; } } return false;}
int main(){ vector<int> arr{ 1, 2, 3, 4, 5 }; int item = 3; cout << (binary_search(arr.begin(), arr.end(), item) ? "True" : "False");}namespace ConsoleApp1{ internal class Program { // 手写版 - 可自行练习 static bool BinarySearch(int[] arr, int item) { int left = 0; int right = arr.Length - 1;
while (left <= right) { int mid = left + (right - left) / 2; if (arr[mid] == item) { return true; } else if (arr[mid] < item) { left = mid + 1; } else { right = mid - 1; } } return false; }
static void Main(string[] args) { int[] arr = [1, 2, 3, 4, 5]; int item = 3; Console.WriteLine(Array.BinarySearch(arr, item) >= 0); } }}常见的有线性查找和任何将内容循环一遍的叙述
对于未排序数据,从头到尾查找数组内容
说明:
例如从1~100找一个数字,从1开始,逐一检查每个数字,直到找到目标或结束
示例:
在未排序数组 arr 中找到元素 item 的索引,若不存在则返回 -1
#include <iostream>#include <algorithm>#include <vector>using namespace std;
int main(){ vector<int> arr{ 12, 43, 56, 78, 9 }; int item = 9; auto it = find(arr.begin(), arr.end(), item); if (it == arr.end()) { cout << -1; return 0; } cout << distance(arr.begin(), it); return 0;}namespace ConsoleApp1{ internal class Program { static void Main(string[] args) { int[] arr = [12, 43, 56, 78, 9]; int item = 9; Console.WriteLine(Array.IndexOf(arr, item)); } }}arr = [12, 43, 56, 78, 9]item = 9try: print(arr.index(item))except ValueError: print(-1)O(n log n)
Section titled “O(n log n)”基本的快速排序法的平均复杂度,不过快速排序在极端情况下,比如数据已经排序好时,最坏情况是O(n²)
快速排序法是一种当前常见的排序算法
说明:
- 选择一个基准值(pivot)
- 所有比pivot小的放在它前面,比pivot大的放在后面
- 分别对pivot的左右两边重复上述动作,直到子数组长度<=1
示例:
使用C++内置的快速排序法,将数组 arr 递增排序
#include <iostream>#include <algorithm>#include <functional>using namespace std;
int main(){ // qsort是C函数,比较器的参数类型较复杂,而C++可以直接使用sort()进行默认的不指定排序 int arr[] = { 5, 2, 9, 1, 5, 6 }; qsort(arr, sizeof(arr) / sizeof(arr[0]), sizeof(int), [](const void* a, const void* b) {return *(int*)a - *(int*)b; }); return 0;}常见的有冒泡排序法,但两层for循环就是最明显的n²形式
冒泡排序法是一种较慢的排序方法,适合学习用途
说明:
- 循序读取数组,将相邻元素两两比较
- 如果前面大于后面,则交换它们 (递增)
- 重复以上操作直到没有交换发生
示例:
使用冒泡排序法将长度为 n 的数组 arr 递增排序
#include <iostream>using namespace std;
int main(){ int arr[] = { 5, 2, 9, 1, 5, 6 }; int n = sizeof(arr) / sizeof(arr[0]); bool swap = true; while (swap) { swap = false; for (int i = 1; i < n; i++) { if (arr[i - 1] > arr[i]) { int temp = arr[i]; arr[i] = arr[i - 1]; arr[i - 1] = temp; swap = true; } } } return 0;}namespace ConsoleApp1{ internal class Program { static void Main(string[] args) { int[] arr = [5, 2, 9, 1, 5, 6]; int n = arr.Length; bool swap = true; while (swap) { swap = false; for (int i = 1; i < n; i++) { if (arr[i - 1] > arr[i]) { int temp = arr[i]; arr[i] = arr[i - 1]; arr[i - 1] = temp; swap = true; } } } } }}主要有矩阵乘法以及三层循环n的操作,比如Floyd-Warshall算法
Floyd-Warshall算法
Section titled “Floyd-Warshall算法”Floyd算法用于求任意两点间的最短路径
说明:
涉及后面会提到的图论,这里只说明关键内容
如果 i 到 j 的距离大于 i 到 k 再到 j 的距离,则将 i 到 j 的距离更新为 i 到 k 再到 j
示例:
Floyd-Warshall的核心代码
for(int i = 0; i < n; i++) { for(int j = 0; j < n; j++) { for(int k = 0; k < n; k++){ if (dist[i][j] > dist[i][k] + dist[k][j]) { dist[i][j] = dist[i][k] + dist[k][j]; } } }}全排列以及一些暴力解法
说明:
将数组的内容按顺序输出所有可能的排列方式
示例:
使用Python的itertools排列函数permutations生成
import itertools
arr = [1, 2, 3]print(*itertools.permutations(arr))/*(1, 2, 3) (1, 3, 2) (2, 1, 3) (2, 3, 1) (3, 1, 2) (3, 2, 1)*/空间复杂度较简单,将数据大小乘以使用数量就是实际占用量,比如 n = 1024 创建一个 int arr[n] 就是用了4 bytes × 1024 = 4096 bytes
在编写代码时一般会将使用的数组大小声明好,可以明确看出内存使用量。